Regular Expressions in Python
The regular expression is a distinctive sequence of characters, which helps users match or find other strings or sets of strings, using a special syntax seized in a pattern. It is a persuasive language to match text patterns.
History
In 1951, a mathematician named Stephen Cole Kleene termed the concept of a regular language as a language, which is detectable by a finite automaton and strictly expressible using regular expressions. In the mid-1960s, a computer science veteran Ken Thompson, one of UNIX’s inventors, implemented array matching in the QED text editor using Kleene’s method.
Since then, regexes have appeared in many editors, codes, programming languages, and tools as a means of determining if a string matches a defined pattern. Python, Java, and Perl all upkeep regex functionality, like most UNIX tools and many script editors.
Regular Expression in Python
Regular Expressions often termed as regex, are an arrangement of characters used to verify whether a pattern exists in a given string or not. If users have ever used replace tools, search and search engines of word processors and text editors - they have already seen regular expressions in use. Regex is working on the server-side to validate the format of email addresses or passwords during recordkeeping, used for analyzing text data files to find, replace, or delete the specific string. It helps control textual data, which is often a prerequisite for data science developments involving text mining.
In Python, regular expressions are supported by the re library. It means that if users want to start using them in Python scripts, the user has to import re module with the help of import Library.
Import re
The re library in Python provides numerous functions, making it very handy in different aspects of programming.
Basic Characters Pattern
Users can easily tackle many fundamental challenges in Python using basic characters. Basic characters are the simplest regular expressions. It matches themselves precisely and does not have a special implication in their syntax.
Examples are ‘A’, ‘a’, ‘X’, ‘5’.
Basic characters can perform simple exact matches:
pattern = r"Cookie"
sequence = "Cookie"
if re.match(pattern, sequence):
print("Match!")
else: print("Not a match!")Result: Match
Match()
The match() function returns a match parameter if the text matches its pattern. Otherwise, it returns Null hence, nothing. The ’re’ library covers several other functions, which have been discussed in the latter part of this topic.
Notice the r at the start of the pattern Cookie?
It is known as a raw string literal. It changes the interpretation of the string literal.
For example, it is just a backslash when prefixed with an r rather than explains as an escape sequence. The grammar involves backslash-escaped characters, and to avoid these characters from elucidating as escape sequences. A programmer uses the raw ’r’ prefix.
Special Characters Pattern
Characters that do not match themselves as seen but have a special implication when castoff in a regular expression. For better understanding, Special Characters are reserved meta-characters, which indicate something else and not what they look alike.
Let us discuss some examples to see the special characters with the use of Python inbuilt functions.
Search ()
Search() with the search function, the user search through the given string/sequence, observing for the first location where the regular expression produces a match.
Group ()
It returns the string matched by the re Users may see both these functions in more detail in the forthcoming examples.
'.' Period
The Period matches any single character except the newline character.
re.search(r'Co.k.e', 'Cookie').group() Result= ‘Cookie’
'^' A caret
It matches the start of the string.
re.search(r'^Eat', "Eat cake!").group() Result= ‘Eat’
'$' Dollar Sign
The dollar sign matches the end of the string.
re.search(r'cake$', "Cake! Let's eat cake").group() Result= ‘cake’
'\' Backslash
A backslash is the most diverse meta-character as, If the character succeeding the backslash is a standard escape character, then the special meaning of the term is occupied.
Else, if the following character, the backslash is not a recognized escape character, then the user may treat backslash like any other character and passed through.
Concepts of Grouping & Non-Grouping
The group feature of regular expression enables the user to pick up chunks of the matching text. Parts of a regular expression pattern constrained by parenthesis () are called groups. The parenthesis does not modify what the expression matches but rather forms groups within the matched structure. The plain match. Group () without any argument is still completely matched text as usual. Let go through a simple example to understand this concept. Imagine users were validating email addresses and want to check the user name and host. It refers to when the user would want to create a different group within the user’s matched text.
Statement = 'please contact us at: support@gmail.com'
Match = re.search(r'([\w\.-]+)@([\w\.-]+)', statement)
If statement:
Print ("Email address:", match.group()) # The whole matched text
Print ("Username:", match.group(1)) # The username (group 1)
Print ("Host:", match.group(2)) # The host (group 2)Output
Email address: support@gmail.com Username: support Host: ibex.co
Concepts of Greedy & Non-Grouping
A greedy match is when an exceptional character matches as much of the search sequence as probable. It is the normal conduct of a regular expression, but sometimes this behavior is not preferred:
Pattern= "cookie" Sequence= "Cake and cookie" Heading= r'<h1>TITLE</h1>' re.match(r'<.*>', heading).group()
Output: TITLE
The pattern <.*> matched the whole string, right up to the second incidence of >.
However, if the user only wanted to match the first <h1> label, the user could have used the greedy qualifier ’*?’ that matches as little script as possible.
Adding '?' after the qualifier marks the match in a non-greedy or insignificant fashion; That is, as few alphabets as possible would match. When the user runs <.*>, the user would only get a match with <h1>. Heading= r'<h1>TITLE</h1>' re.match(r'<.*?>', heading).group()
Output: ‘<h1>’
Compilation Flag
Distinct a flag value may modify an expression’s behavior. Users can add flags as an additional argument to different functions to perform the compilation of tasks. Some of the more useful ones are:
IGNORECASE (I)
Allows case-insensitive matches.
DOTALL (S)
It allows ‘.’ to match any character, including the newline.
MULTILINE (M)
It allows the start of the string (^) and end of a string ($) presenter to match newlines as well.
VERBOSE (X)
Allows the user to compose whitespaces and comments inside a regular expression to make it more understandable.
Statement = "Please contact us at: support@gmail.com, xyz@gmail.com" #using the VERBOSE flag helps understand complex regular expressions Pattern = re.compile(r""" [\w\.-]+ #First part @ #, Matches @ sign within email addresses datacamp.com #Domain """, re.X | re.I)
Output
Address: support@ibex.co Address: xyz@ibex.co
Summary Table
It is a lot of information and concepts to grasp. The below-mentioned table summarizes all the user concepts of regular expressions with different Character classes and concepts.
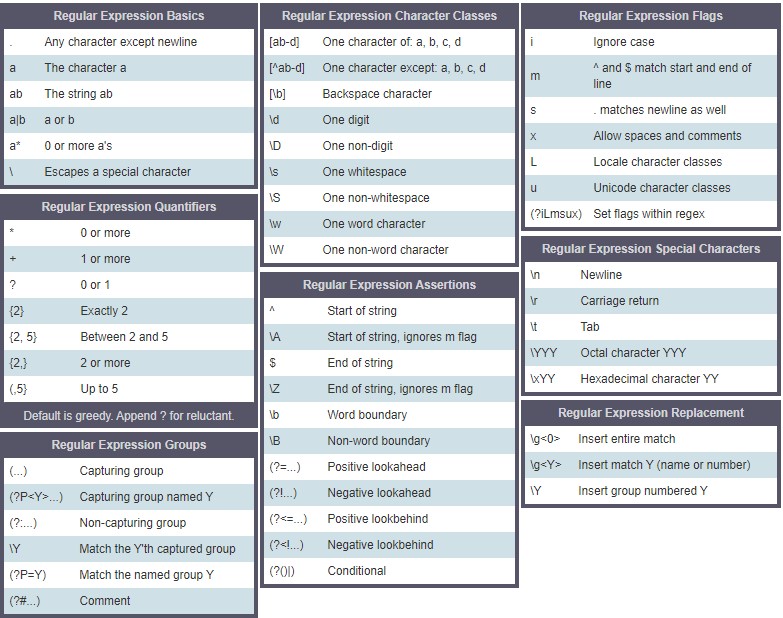
Other useful articles:
- OOP in Python
- Python v2 vs Python v3
- Variables, Data Types, and Syntaxes in Python
- Operators, Booleans, and Tuples
- Loops and Statements in Python
- Python Functions and Modules
- Regular Expressions in Python
- Python Interfaces
- JSON Data and Python
- Pip and its Uses in Python
- File Handling in Python
- Searching and Sorting Algorithms in Python
- System Programming (Pipes &Threads etc.)
- Database Programming in Python
- Debugging with Assertion in Python
- Sockets in Python
- InterOp in Python
- Exception Handling in Python
- Environments in Python
- Foundation of Data Science
- Reinforcement Learning
- Python for AI
- Applied Text Mining in Python
- Python Iterations using Libraries
- NumPy vs SciPy
- Python Array Indexing and Slicing
- PyGame
- PyTorch
- Python & Libraries